お入り
最近、MSAアーキテクチャの成熟度が上がるにつれて、Kubernetes環境を探している人が増えています。これにより、多くの開発者、エンジニアの方々がKubernetesについて深く覗いています。今回のポストでは、Kubernetesアーキテクチャを構成する際に、考慮すべきクラウドベンダーの使用、オートスケーリング戦略、展開戦略などについてご紹介します。
Amazon EKSによるClusterの生成
一般的なKubernetesの構造は下図のように MasterとWoker Nodesで構成されます。
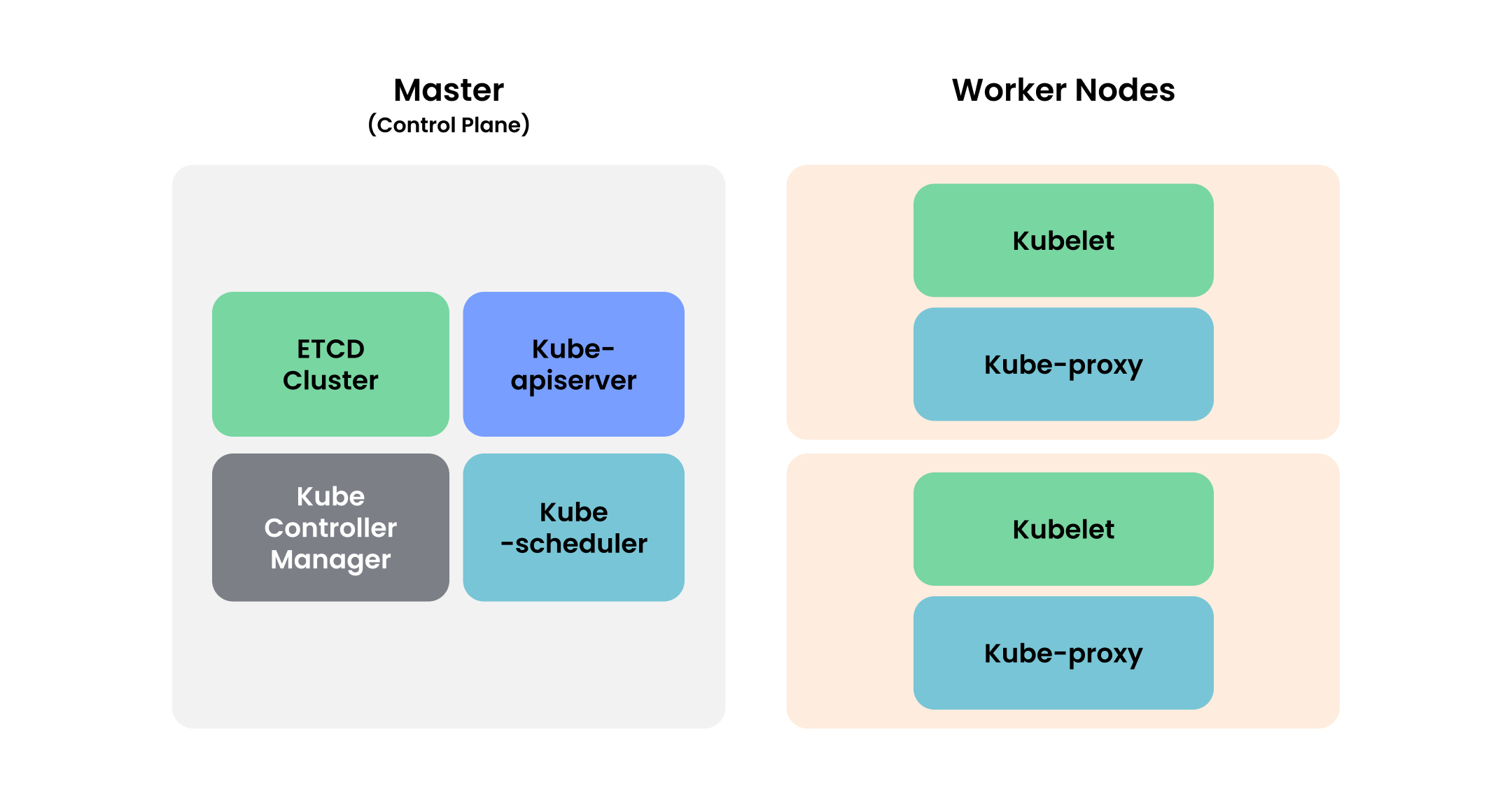
Amazon EKSを使用する場合は、Master Nodeの管理をオペレーターが直接ではなくAWS がサポートします。つまり、クラスターの更新などの複雑な作業も、AWS Consoleで簡単に行うことができます。これだけでなく、Amazon EKSのAutoScalerは、AWSのAuto Scaling Groupを使用してCluster Nodeの数を動的に調整することもでき、モニタリングとロギングも特に設定なしで可能です。しかし、メリットだけがあるわけではありません。
Amazon EKSは Clusterごとに管理費用がかかりますので、小規模なクラスタや単一インスタンスは、EC2で直接クラスタなどの管理的負担が少ない場合、EC2を活用して直接構築を行うことを検討してみることができます。
https://aws.amazon.com/ko/eks/pricing/AutoScailing
安定した運用のためには、AutoScailingは必須です。特にKubernetesはPodに対するAutoScailing、Nodeに対するAutoScailingが同時に適用されていなければ安定して動作します。さらに、流動的なAutoScailingは運用コストの削減につながる可能性があります。
AutoScailing in Kubernetes
Pod AutoScailing - HPA
- HPAコントローラを使用して、Podのマトリックス値に基づいてPodの数(Replicas)を調整します。
Cluster AutoScailing
- Amazone EKSでは、Cluster AutoScailing には AWS AutoScailingGroupとKarpenterを使用した方法があります。このポストでは、AWS AutoScailingGroup を利用する基本的な Cluster AutoScailingについてご紹介します。
-
Cluster Auto Scailing - AWS Cluster Autoscaler
リソース不足でPendingされたPodがある場合は、Auto Scaling GroupにNodeを追加します。
AutoScailing Flow
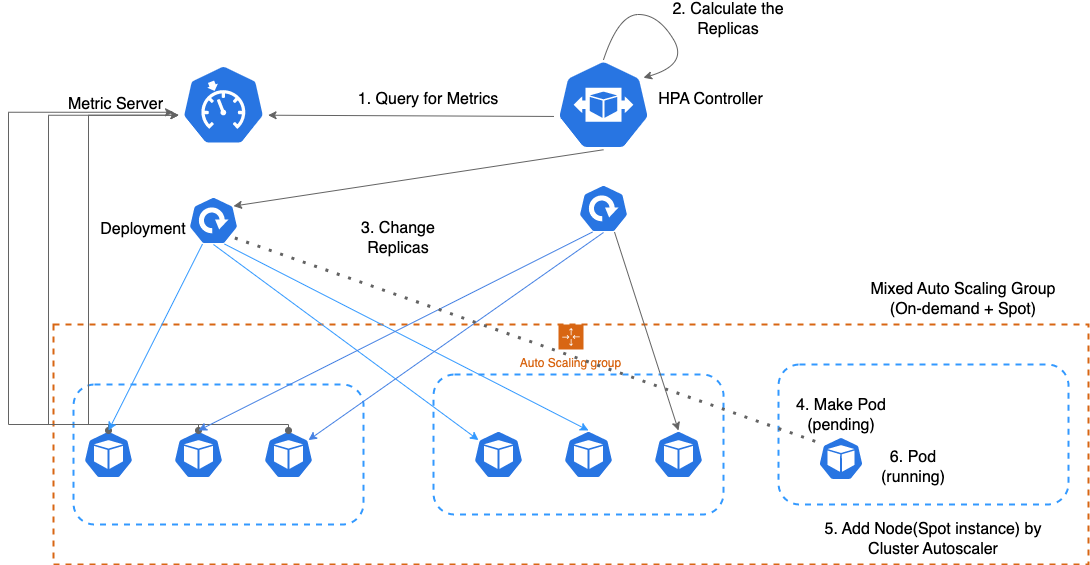
- HPAコントローラは定期的にMetric Serverにクエリをスローします。
- PodのCPU / Memory metricが事前に約束された数値を超えると、Replicasを調整します。
- DeploymentでReplicas、つまりPodの数を更新します。
- DeploymentはReplicasに従って Pod を作成
- Cluster AutoscalerがペンディングされたPodがある場合は、ACSにNodeを追加
- Podを対応するノードに割り当てます。
ここで、すべてのノードのリソースが不足している場合→Pod pending状態になります。
- Pod status : pending → running
AutoScailing戦略:Spot+Ondemand Instanceで費用を最適化
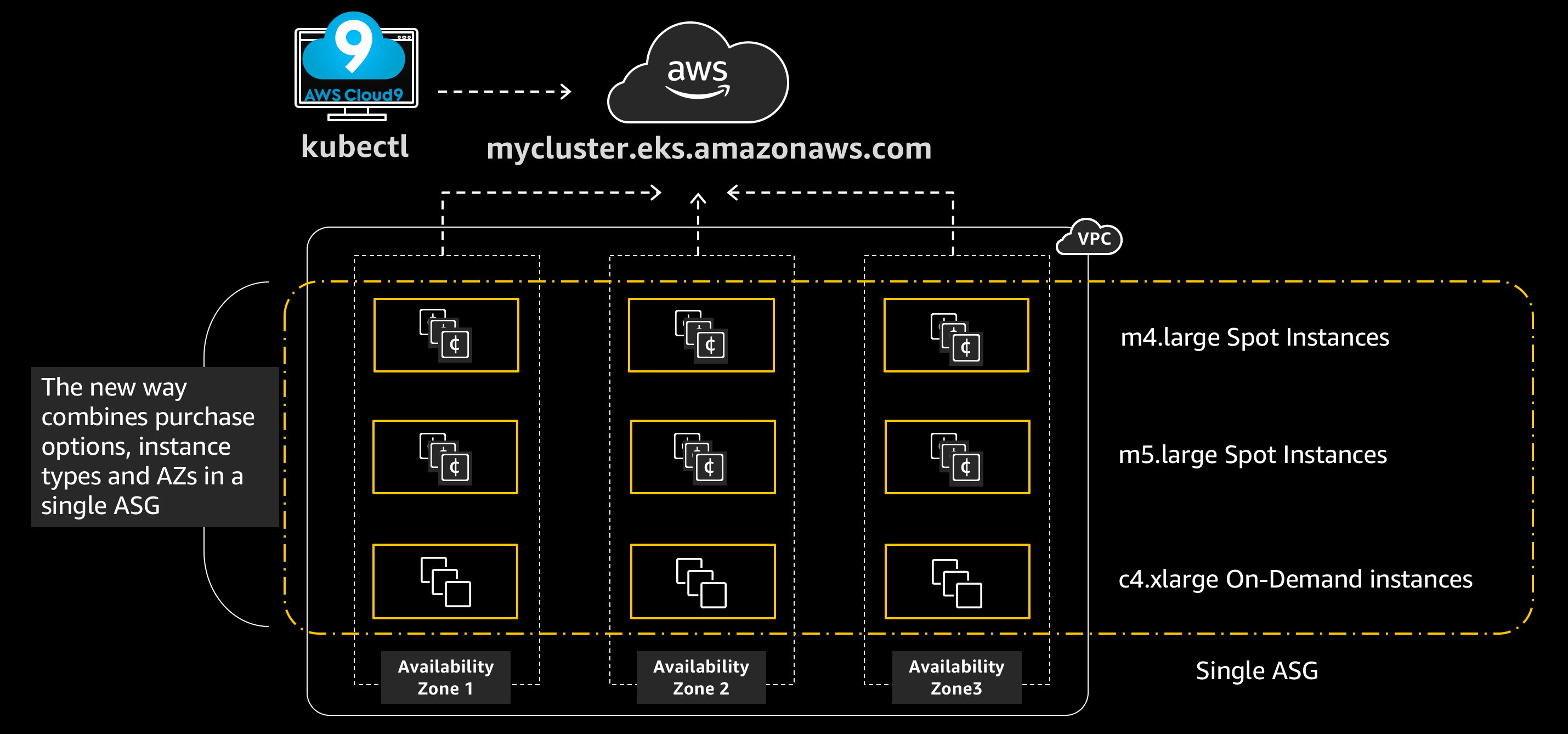 出典 : https://awskrug.github.io/eks-workshop/spotworkers/
出典 : https://awskrug.github.io/eks-workshop/spotworkers/
基本戦略は次のとおりです。
- 安定したサービスのために最小限のOndemand NodeGroupを使用する
- 流動的なトラフィックの増減に備えてSpot NodeGroupを使用する
→ Ondemand Nodeのリソースが枯渇する場合は、Spot Nodeを使用するように
Taintを利用する場合は、OndemandにPodを割り当てることができない場合にのみSpotに割り当てられるように強制できます。
- Spot NodeGroupのTaintをPreferNoScheduleに設定
Spotを使用する際の最大の懸念は、Spot Instanceがいつでも終了できることです。これを防ぐためには、次の措置が必要です。
- 終了することを確認
- まもなく終了予定の場合、Taintを利用してそのNodeにPodが新たに割り当てられないようにする
- そのNodeのPodをDrain
- 残りのNodeにPodを割り当てる
このアクションを可能にするのが AWS Node Termination Handlerです。
IDMS方式を使用すると、DaemonSetとしてインストールされ、すべてのNodeにインストールされ、インスタンスのメタデータを監視し、シャットダウンが予定されている場合は、以前に案内した手順を実行します。(Labelを使用してSpot Nodeにのみ適用)
Deployment
EKSにClusterを作成した後、NodeGroupを作成してAutoScailing戦略を適用した場合、基本的なアーキテクチャの構成は完了です。これで、Kubernetesにアプリケーションをビルド/配布するように、次のアーキテクチャを構成できます。
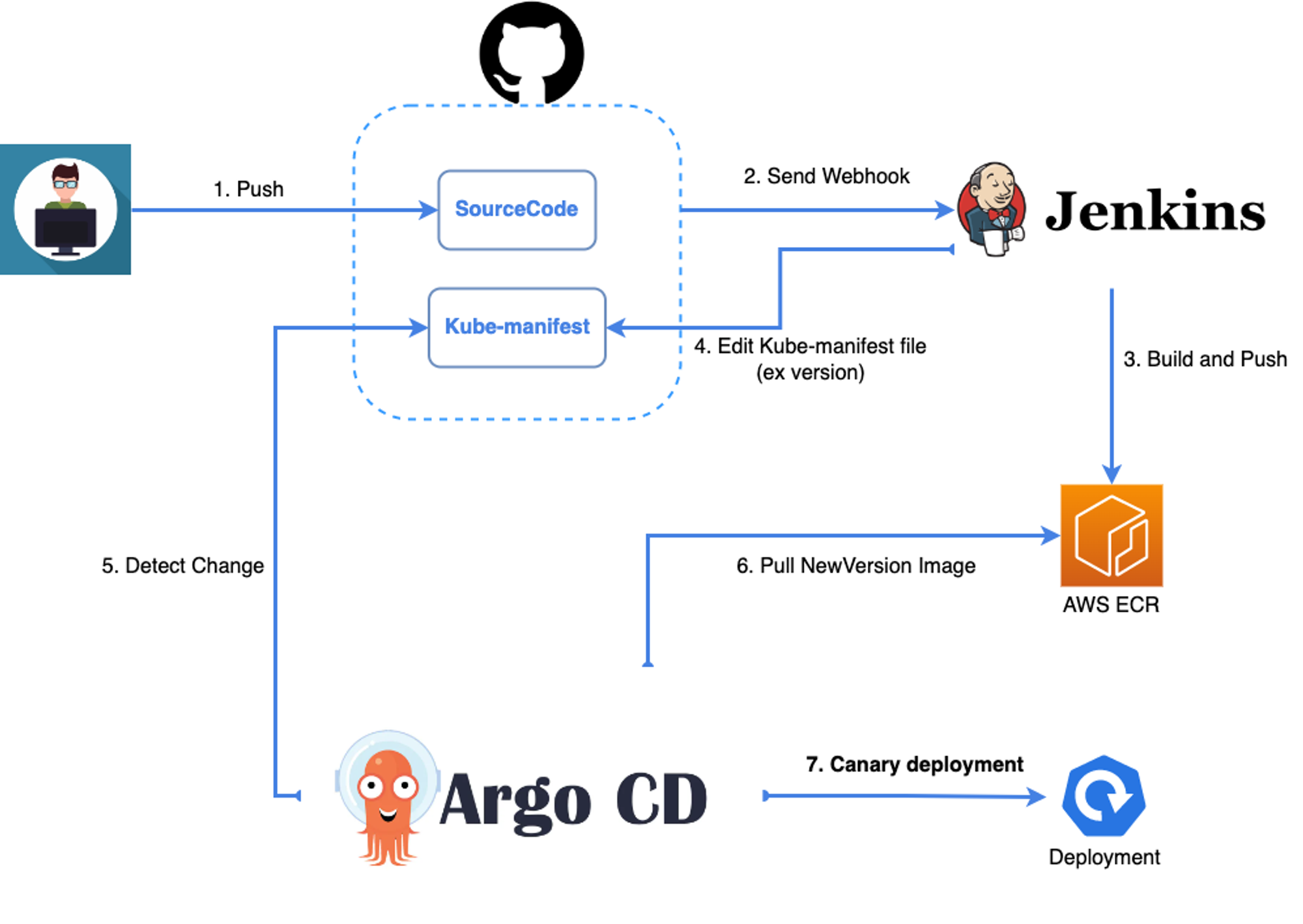
- Github : Sourcecodeと、Kubernetes manifestfileを保存し、SourceCode変更時にJenkinsにWebフックを送信します。
- Jenkins : 変更されたコードを受け取り、イメージをビルドします。→AWS ECRのPush、GithubのKube-manifestのバージョンを変更します。
- Argo CD: Kube-manifestの変更を検出する(Sync)→Canary deploy
- Canary Deploy : 可用性を高めるために、少量のPodのみを配布した後、徐々に配布します。
まとめ
Kubernetes環境自体がLearning Curveが高いため、実際の運用環境への導入を嫌がる方が多いことがわかっています。しかし、遅れたと思うときは、本当の遅いことは、コメディアンのパクミョンス様の言葉のようにさらに遅くなる前にKubernetesの流れに便乗をしなければならない時が今だと思います。
