
SDN 네트워크 가상화 장애
SDN 참고 링크 : https://www.juniper.net/kr/kr/solutions/sdn/what-is-sdn/
현상
시스템 납품 구축 중 솔루션 장애가 빈번하게 접수되는 사례가 발생하여, 원인 분석에 착수하게 되었습니다.
표면적으로 노출되는 사항은 애플리케이션의 통신 불능으로 인한 다량의 로그, Tomcat/Mqtt/MariaDB/ElasticSearch/WhaTap Server Monitoring Agent의 네트워크 단절 현상이 관측되고 있었습니다.
모니터링 상황
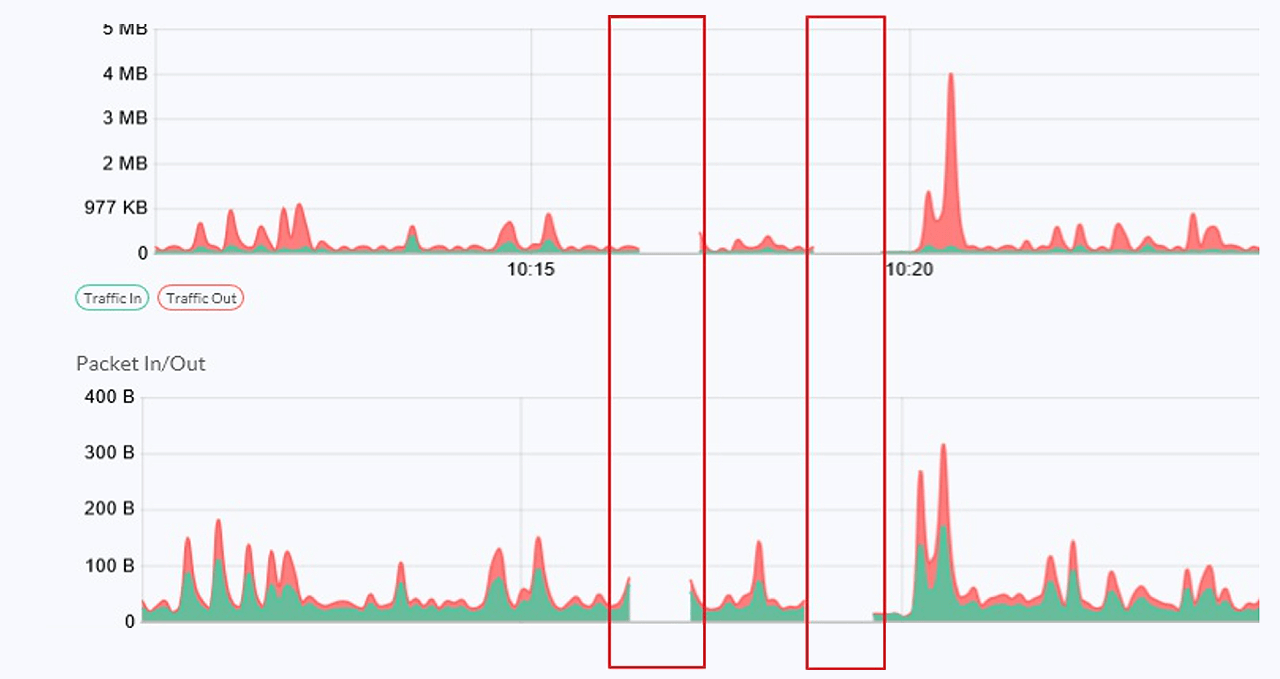
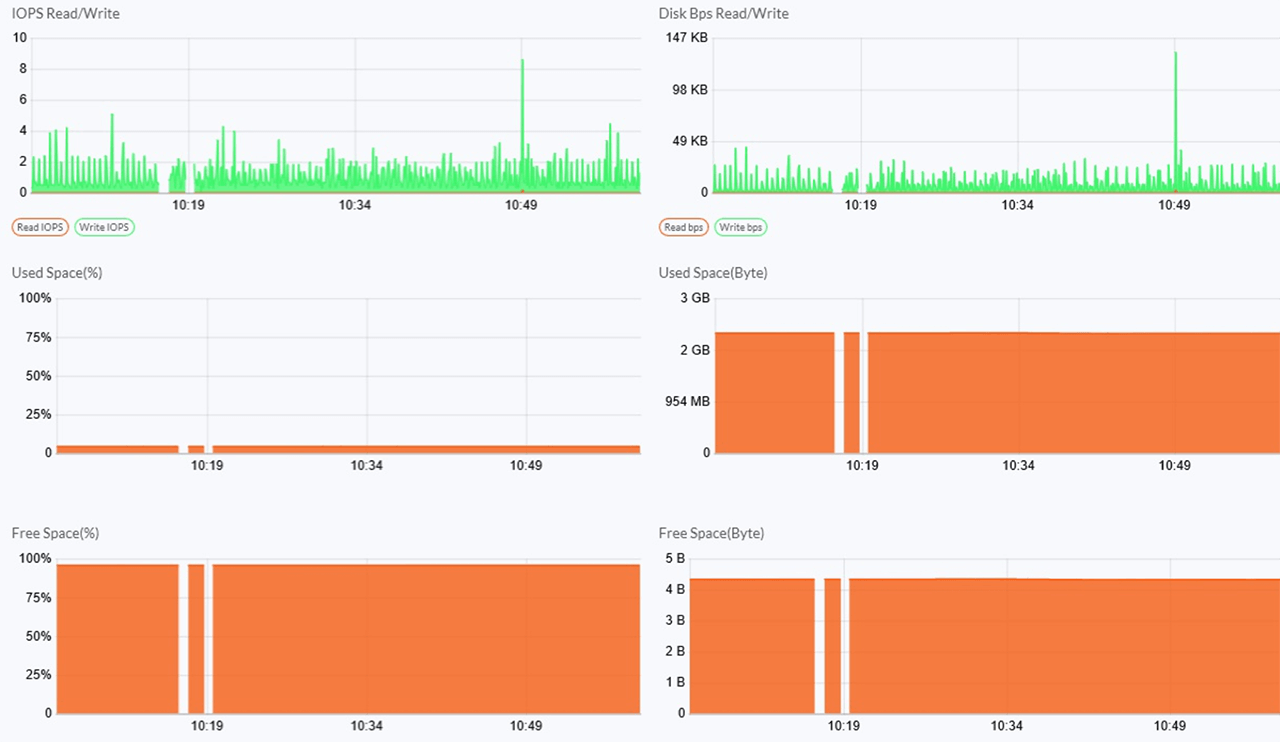
서버 모니터링을 통해 확인되는 바로는 모니터링 데이터가 수신되지 못하여 데이터의 공백 구간 발생이 확인되었습니다.
분석
표면적으로는 서버 모니터링 에이전트의 비정상 동작을 의심할 수 있으나, 시스템 점검 결과 ICMP 프로토콜로의 통신 패킷 유실 등이 관측되어 네트워크 가상화 운영팀에 이를 리포팅 하게 되었습니다.
다만 네트워크 가상화 팀에서는 관련 징후를 탐지할 수 없다는 답변을 받았습니다.
조치
이슈 상황이 해소되지 않는 상태가 지속되어 네트워크 가상화 팀과의 협의를 진행하고, 가상화 서버의 이더넷 재설정이 및 네트워크 가상화 대역을 시스템이 안정적으로 운영되고 있는 대역으로 변경하는 작업이 진행되었습니다.
이를 통해 모든 고객사 시스템이 정상화되어 운영되기 시작했습니다.
시사점
모니터링은 상황에 대한 정보를 왜곡하지 않고 객관적으로 노출시킬 수 있어야 합니다. 서버 모니터링 에이전트의 경우 OS상에 설치되기 때문에 OS 외부에서 발생하는 인프라 레벨의 정보를 확보할 수 없는 제약을 가지게 됩니다. 이런 제약에도 불구하고 시스템 전반의 다수의 장비에 동시에 발생하는 이상 징후는 개별 서버의 모니터링 상에도 나타날 수 있습니다. 본 케이스의 경우 모니터링 입장에서는 데이터 누락이라는 결과로 나타난 케이스가 되겠습니다.
데이터 누락 감지를 통해 인프라 레벨의 장애 징후를 탐지하는 용도로도 활용할 수 있음이 증명된 사례라 하겠습니다.
Disk 사양 변경
현상
자사 내에서 개발팀의 이슈 관리 도구를 운용하기 위한 서버의 자원 사용률이 높게 나타나는 현상이 관측되었습니다.
모니터링 상황
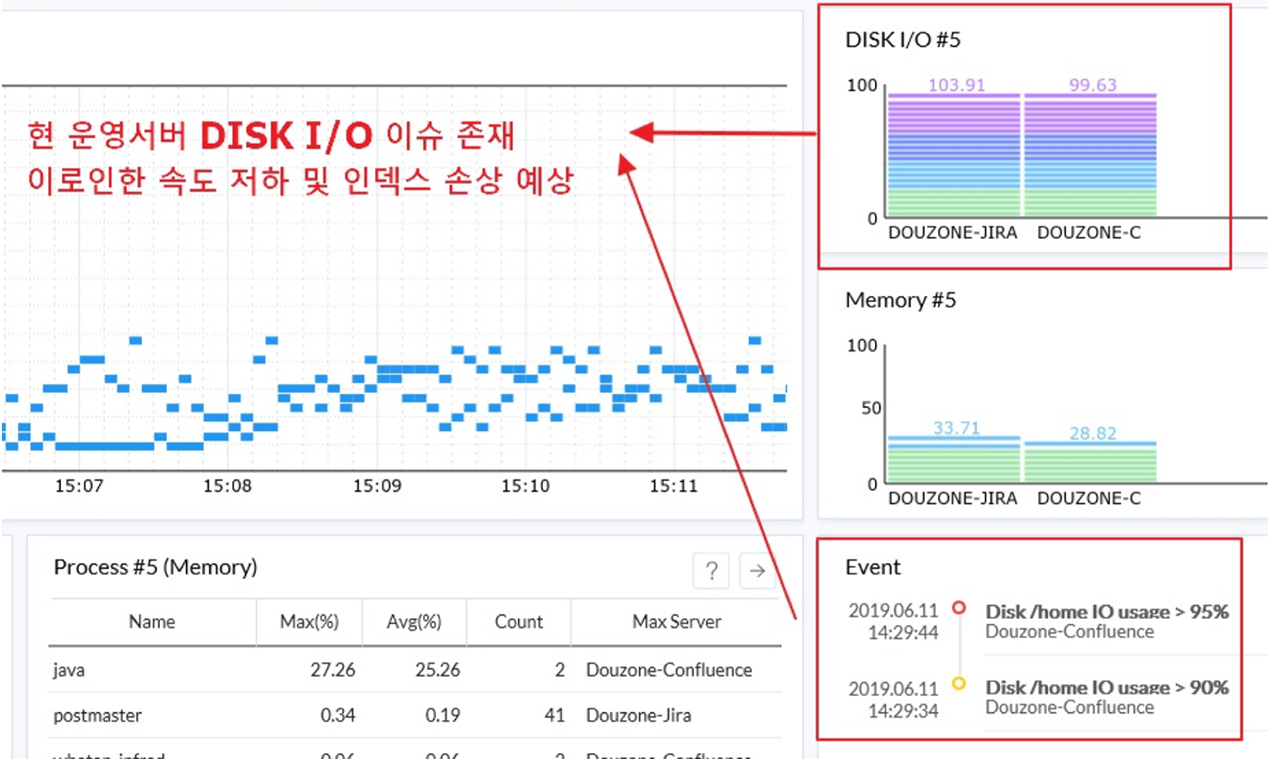
서버 모니터링의 리소스 보드를 통해 가용량 대비 Disk IO가 높은 장비의 현황이 노출되고 있었습니다.
분석
표면으로 노출된 정보를 기반으로, 동일 장비에서 발생한 장애 이력을 검토한 결과 다음과 같은 이상 상황이 발생한 것으로 확인되었습니다.
- 속도 저하 현상 3회
- 인덱스 파일 손상 5회
- Disk full 로그 1회
조치
디스크 IO 이슈 해결을 위해 가장 용이한 대안으로 고가의 장비 도입 안과 HDD를 SSD로 검토하는 안을 고려하였으며, 디스크 용량을 여유있게 운용하기 위한 고려도 필요했습니다. TCO를 고려하여 고가의 장비 도입 안은 폐기하고, SSD는 도입하되 대용량으로 도입하기 어려운 부분은 NAS 스냅샷 백업을 활용하는 안으로 진행하였습니다.
시사점
서버 모니터링의 리소스 보드는 전체 서버의 현황 정보를 요약하여 제공합니다. CPU 이슈가 존재하는 서버의 대수 및 추이를 동시에 감지하기 위한 메인 차트와 OS 모니터링의 주요 요소별 Top 5 목록을 통해 이슈 발생 가능성이 높은 대상 자원을 노출시키며, 서버에서 발생한 알림 내역을 최신 순으로 표시하고 있습니다.
모니터링 대상 자원 규모가 적은 상황에서는 서버 단위의 상세정보를 파악하기 용이한 기능이 필요하겠습니다만, 대규모 시스템을 모니터링 해야 하는 경우라면 주요 정보를 간결하고 이슈 위주로 보기 위한 대시보드를 필요로 하게 됩니다.
본 케이스는 와탭의 리소스 보드를 활용하여 시스템의 주요 이슈 사항을 수고롭지 않게 탐지한 사례로 볼 수 있겠습니다.
권장 사양으로 스펙 업
현상
고객사 환경에 솔루션 구축 이후 사용자 접속 불가에 따른 장애 분석 및 조치 요청이 접수되었습니다. 본 고객사 환경에는 당초 솔루션 구축 시에 제시한 권장 사양 미달 서버로 구축된 바 있습니다.
모니터링 상황
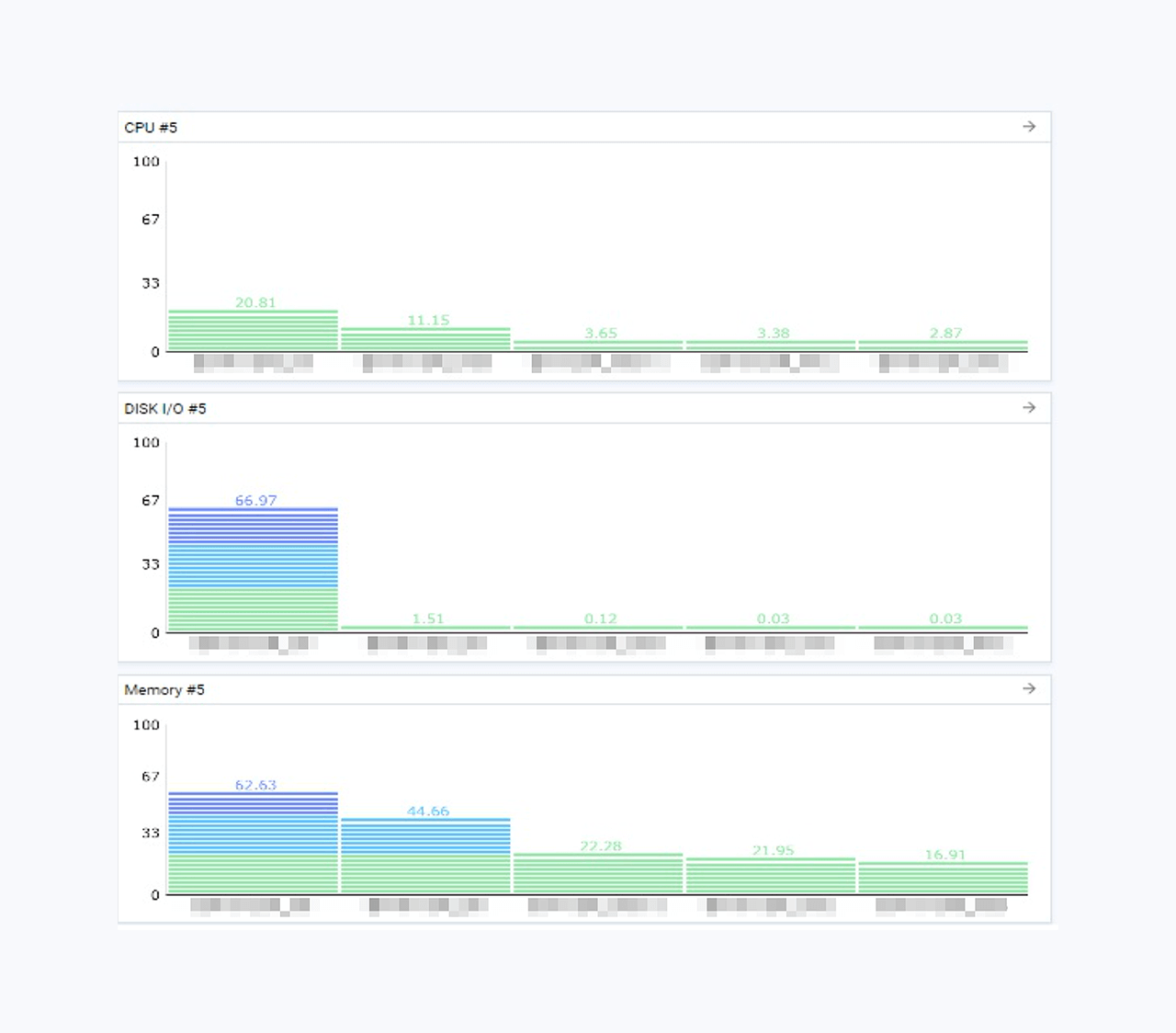
조치 전 디스크 모니터링 상세 정보를 통해 확인한 결과 DISK IO가 100%에 달하는 상황이 지속적으로 관측되었으며 Disk Read/Write 발생으로 인한 부하 상황이 관측되었습니다.
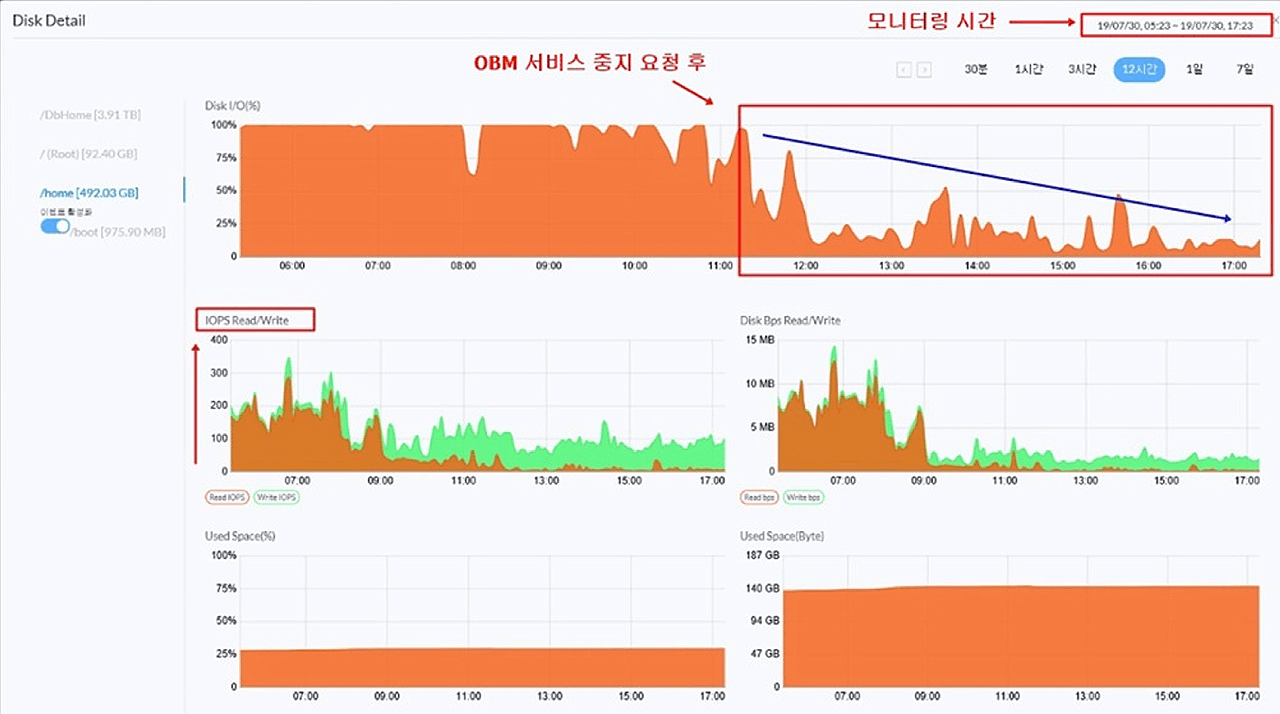
리소스보드를 통해 확인한 CPU, Disk IO, Memory 사용률 현황은 다음과 같았습니다.
분석
본 사이트에 설치된 온사이트 백업 솔루션을 중지한 상황과의 DISK IO 부하 차이를 확인을 통해, 백업 솔루션의 실행중에 나타난 현상으로 확인되었습니다. 단, 본 현상은 권장 사양에 미달하는 기준의 서버로 시스템을 구축하여 기인한 것으로 최종 확인되었습니다.
조치
- 백업 수행으로 Disk IO 및 CPU 과다 사용이 유발되는 경우 “ionice” 명령을 통해 우선 순위를 조정하는 방식을 적용하기도 합니다.
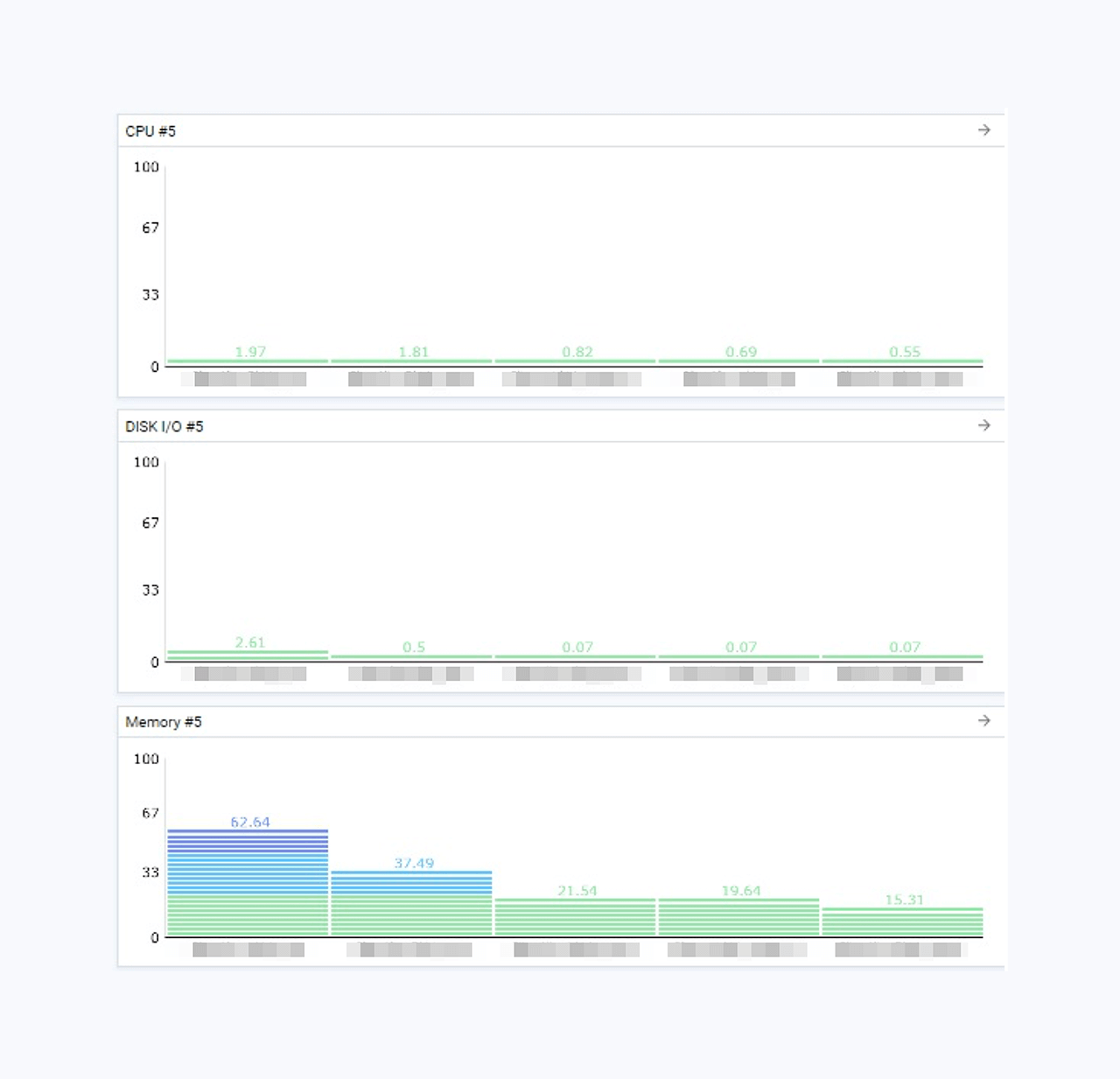
ionice 참고링크 : https://linux.die.net/man/1/ionice - 권장 사양에 근거하여 서버의 SSD 교체 작업을 수행하였습니다. 아울러 선행(pro active) 대응의 일환으로 권장 사양에 따라 CPU 증설 작업도 진행하였습니다. 이후 사용률은 CPU 사용률 및 Disk IO가 현저히 낮아지는 결과로 나타났습니다.
시사점
서버 상세 모니터링의 상세보기 기능은 CPU, Memory, Disk, Network의 카테고리 별로 보다 상세한 정보를 제공합니다. 각 카테고리의 세부 지표의 장기 추이 확인은 통해 사용자는 이후 어떤 조치를 취해야 할지에 대한 객관적인 근거를 마련할 수 있습니다.
본 사례는 Disk I/O 사용률에 더해 IOPS 관점과 Bps 관점의 Disk Read/Write 추이를 통해 특정 시점에 실행된 프로그램이 OS에 미치는 영향을 확인하고 이에 대한 조치 방안을 마련하였던 사례로 볼 수 있겠습니다.
감사의 글
위 사례는 더존비즈온의 윤호민 차장께서 더존비즈온에 구축된 와탭 모니터링을 통해 고객에 서비스를 제공하는 과정에서 활용한 자료를 제공받아 작성하였습니다.
귀중한 글 제공해 주신 윤호민 차장께 감사의 인사 드립니다.
서버 모니터링을 통해 인프라의 이상 징후를 선행 탐지하거나,
서버 자원의 용량 산정 근거를 확보하고자 한다면?
와탭 무료로 시작하기

- 서영일([email protected])
- Development TeamLead Developer