
サービスを運営中なら一度は体験してみたと思う障害。 実際、すべてのサービスに障害が発生します。逃したバグなどの内部要因からインフラ問題などの外部要因まで、さまざまな原因により障害が発生します。 障害が発生したときは、何よりも早く対処することが重要です。 私たちのサービスに障害が発生したとき、どのようにうまく対応しているのか気になりませんか? 今日は実際の数値で私たちの障害対応能力を確認できる指標をご紹介します。
障害対応能力が確認できる指標MTTD/MTTR/MTTF/MTBF
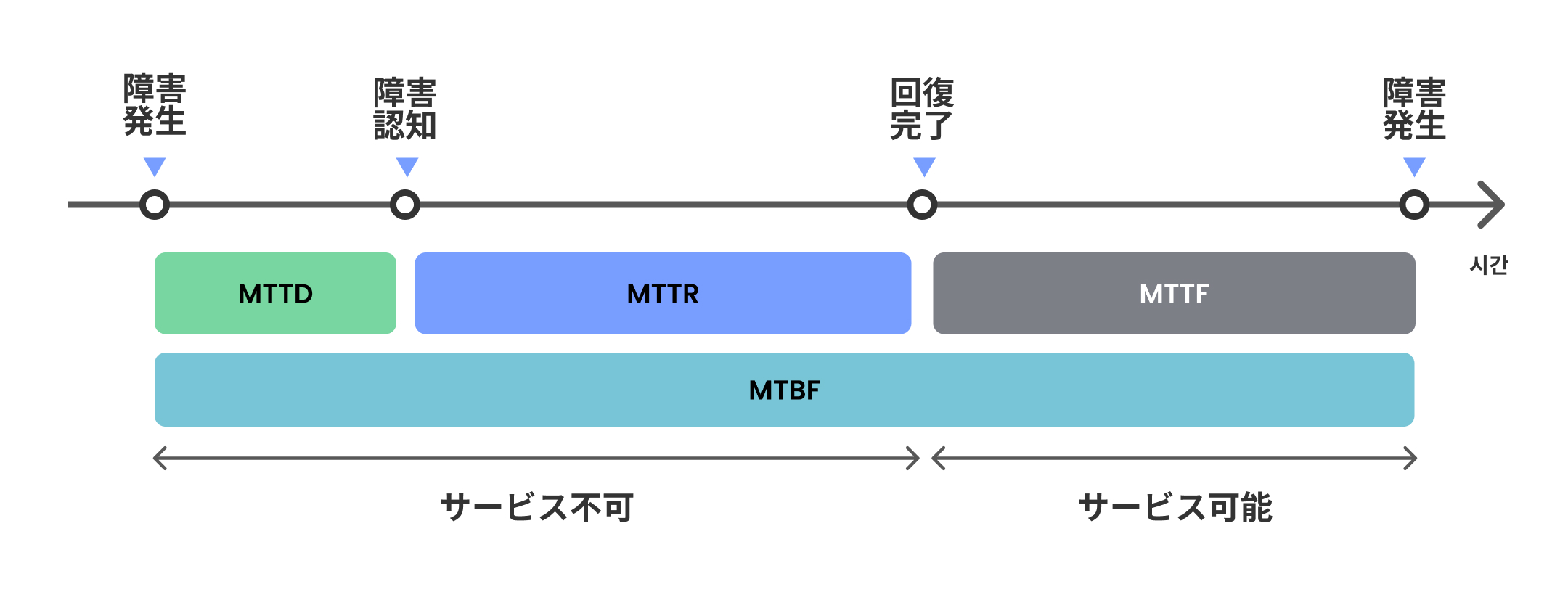
MTTD (Mean Time To Detect)
MTTD は、Mean Time To Detect の略で、通常、ソフトウェア システムでサービス状態の侵害や脅威を検出するのにかかる平均時間を測定するために使用されます。システムまたはネットワークの初期パフォーマンスの低下が発生した時点から、チームが障害または事故を認識した瞬間までの経過時間を示します。迅速に障害を検出する必要があり、脅威を抑え、ダメージを最小限に抑えるための措置をより早く取ることができるため、MTTDは追跡するべきの重要な指標です。
MTTDは通常時間または日単位で測定され、組織運営の全体的な効率を評価できます。パフォーマンスの低下を効果的に検出し、ダウンタイムを最小限に抑える操作が効果的なのかについて確認します。パフォーマンスの低下やインシデントの検出にかかる平均時間を測定するためにMTTDを使用します。
MTTR (Mean Time To Repair)
MTTRは、Mean Time To Repairの略で故障したシステムを修復し、通常の動作状態に復元するのにかかる平均時間を測定するために使用される指標です。MTTRは、エンジニアリングとメンテナンスにおける修理プロセスの効率を評価し、改善の機会を特定するためによく使用されます。MTTRは、ダウンタイムを短縮し、応答時間を改善するなど、メンテナンスプロセスで改善が必要な部分を特定するのに役立ちますので、追跡する重要な指標です。さらに、MTTRはMTBFなどの他の信頼性指標と組み合わせて使用して、信頼性とメンテナンス要件をより完璧に把握できます。
MTTRは通常、障害による総ダウンタイムを修理イベントの数で割って計算します。 結果値は、システムまたはコンポーネントを修理するのに必要な平均時間を表します。顧客が満足できるようにサービスが常に稼働していることを確認したい場合や、故障したシステムやコンポーネントを修理して正常な動作状態に戻すのにかかる平均時間を測定するための指標としてMTTRを使用します。
MTTF (Mean Time To Failure)
MTTFは、Mean Time To Failureの略で、平均利用可能時間という意味で、製品またはシステムが障害が発生するまで動作できる平均総時間を推定するために使用される信頼性測定指標です。システムの信頼性が高いほど、MTTFも長くなります。MTTFは、エンジニアリングおよび製品開発におけるコンポーネントまたはシステムの予想寿命を評価するためによく使用され、メンテナンススケジュール、交換戦略、および全体的な設計に関する決定をすることに役立ちます。
MTTFは通常、製品またはシステムで一連のテストまたはシミュレーションを実行し、各インスタンスに対して障害が発生するまでの時間を記録して計算します。その後、MTTFは記録されたすべての障害時間の平均として計算されます。たとえば、組織に4台のコンピュータがあり、各コンピュータが10ヶ月、4ヶ月、16ヶ月、3ヶ月間続いた場合、MTTFは次のようになります。(10 + 4 + 16 + 3)/4 = 8.25ヶ月のMTTFを持つということです。
MTBF (Mean Time Between Failure)
MTBFは、平均時間ビートフェイルアの略で、平均故障時間を意味し、製品またはシステムが2つの連続故障の間で動作する平均時間を推定するために使用される信頼性測定指標です。このMTBFが長いほど、サービスの信頼性と通常の動作性能が向上します。MTBFは、エンジニアリングおよび製品開発におけるコンポーネントまたはシステムの信頼性を評価し、最適なメンテナンススケジュールを決定するためによく使用されます。 MTBF は、製品またはシステムの総動作時間を、その期間中に発生した故障回数で割って計算します。結果値は、2つの連続障害間の平均時間を表します。
結局、企業はどうすればMTTFを最大限に増やすことができるのか、MTTRはどのようにすればさらに減らすことができるのかを講じなければなりません
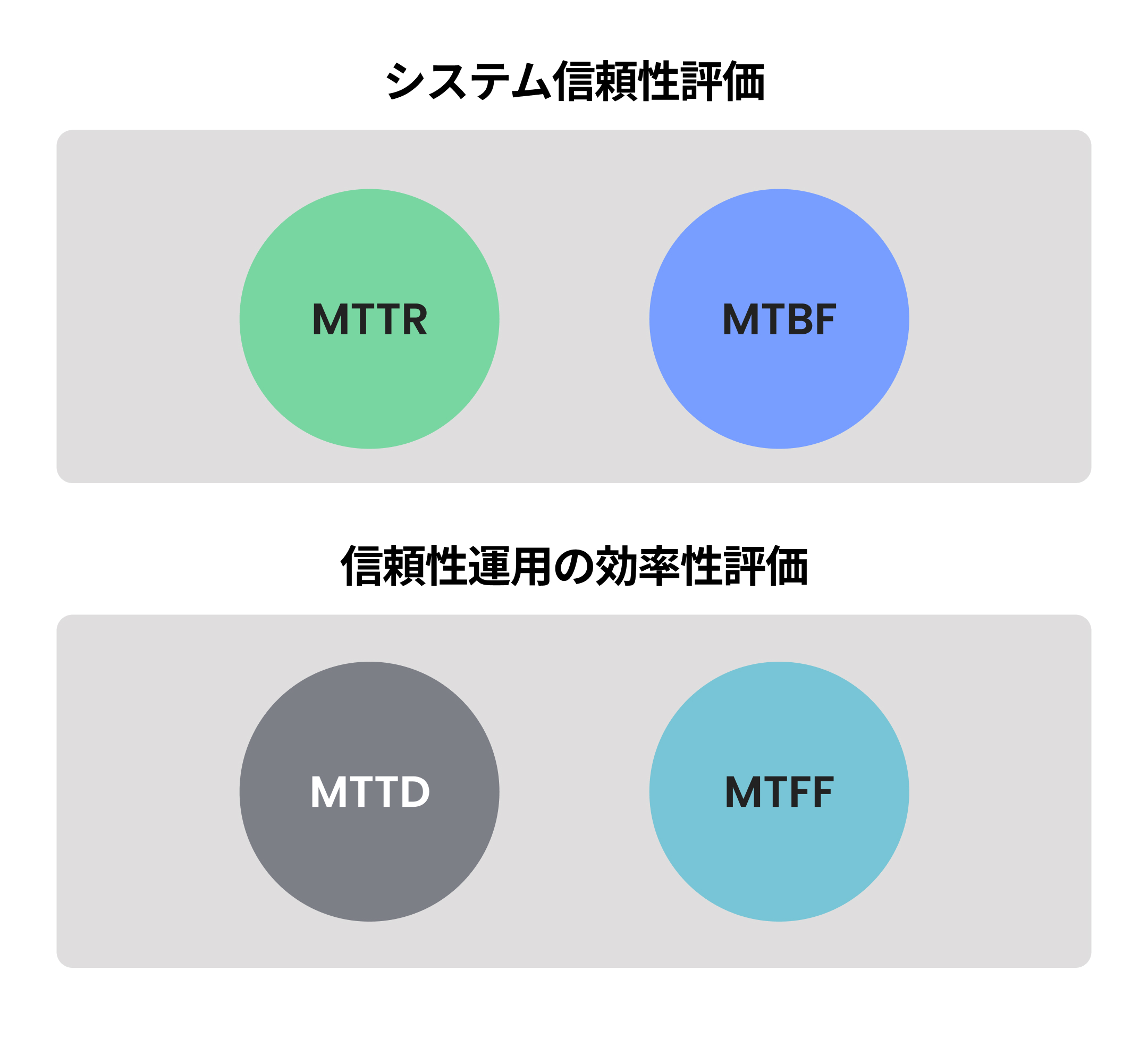
システムの信頼性と信頼性運営の効率性を評価する方法
MTBF、MTTR、MTTD、MTTF は互いに関連されていますが、システムまたはコンポーネントの信頼性と可用性の異なる側面を測定します。ただし、併用すると、システムのパフォーマンス、診断、およびメンテナンスの要件を包括的に把握できます。
たとえば、MTBFと MTTRは、システムの信頼性を評価する際に一緒に使用されることがよくあります。 MTBFは 連続した2 つの故障の間の予測時間を推定し、MTTRは故障したコンポーネントを修復するのにかかる時間を推定します。エンジニアはMTBFとMTTRを比較して、故障間の予想時間と比較して修理時間が合理的であるかどうかを判断できます。
さらに、MTTDと MTTFは、信頼性運営の効率を評価するためによく使用されます。MTTDはパフォーマンスの低下やインシデントを検出するのにかかる平均時間を推定し、MTTFはインシデント間の平均時間を推定します。 MTTDとMTTFを追跡することで、SREおよびDevOpsチームは、検出および対応プロセスで改善が必要な部分を特定できます。
障害との戦争、私たちがモニタリングをしなければならない理由
これら4つのメトリックをまとめると、システムまたはコンポーネントの安全性、可用性、および保守性のより完全な図が得られます。 組織はこれらのメトリックを使用して、メンテナンススケジュールを最適化し、改善の機会を特定し、インシデントメトリックを決定し、設計およびメンテナンス戦略に関するデータ駆動型の意思決定を行うことができます。
多くの組織が障害との戦争を減らし、顧客に集中できる時間を増やしたいと考えています。 そのため、エンジニアは戦略的統合可視性のコアパフォーマンス指標を活用して、システムの中断の根本的にな原因をより迅速に特定し、問題解決にかかる時間を短縮できます。通常、多くの障害通知を受ければより多くの戦争を起こすと思いますが、実際に迅速に問題を解決する場合、直接的に通知疲労の減少も減るそうです。
システムの安定性に関する重要なパフォーマンス指標を理解することは、デジタル復元力を確保するために非常に重要です。これらの指標を追跡することで、組織は応答時間を改善し、通知の疲労を減らし、より良い顧客体験を提供できます。しかし、毎回すべてのサービスがうまくいくかどうかを確認するのは難しいです。そのため、私たちはモニタリングサービスを利用する必要があります。
WhaTapは、リアルタイムで障害を検出できるモニタリングプラットフォームです。 アプリケーション、サーバー、DB、ブラウザ、Kubernetes、ログ、クラウドネットワークのパフォーマンスまで、1つのプラットフォームで確認できます。 今15日間無料体験で「WhaTap Monitoring」をお試しください!
